
Setting the scene
Imagine you are a data platform team, about 2 years ago, at the start of 2020. Corona has just hit the scene but there is one thing you just discovered that is keeping morale high:
It’s dbt.
dbt proved to make a lot of your data transformations a lot easier to maintain, and a lot quicker to execute with incremental table materialization being the top contributor to this improvement.
Back then when you entered dbt in Google, you were not directed to the dbt website, but to a Wikipedia page about evidence-based psychotherapy. And just as limited as Google’s visibility of the dbt we know and love today was your understanding of how to write incrementals that will not make any incident mitigation an enormous and pretty terrible manual or costly ordeal.
This blog post exists to give you a little insight into what we learned how to write a robust incremental, that very easily can recover data in the past so you don’t have to pull your hair every time a data source adds data after the fact of initially integrating it.
Quick summary on dbt, and why incrementals are brilliant
Taken from the dbt documentation, dbt (data build tool) enables analytics engineers to transform data in their warehouses by simply writing select statements. dbt handles turning these select statements into tables and views.
dbt does the T in ELT (Extract, Load, Transform) processes – it doesn’t extract or load data, but it’s extremely good at transforming data that’s already loaded into your warehouse.
So what is an incremental?
Incrementals are one way of materializing data.
Taken from the dbt documentation, an incremental models are built as tables in your data warehouse. The first time a model is run, the table is built by transforming all rows of source data. On subsequent runs, dbt transforms only the rows in your source data that you tell dbt to filter for, inserting them into the target table which is the table that has already been built.
This is so great because it allows you to only the process the data that is new instead of going through your all time data. As you can imagine, for bigger datasets and complex transformations this can speed up the process by a lot, which is why we started using it excessively when we adopted dbt.
Disclaimer
At Kolibri we are using Snowflake, which supports the merge strategy for incremental models. If you are on a database that does not support this, take this blog post with a grain of salt.
A very basic incremental model
This model is adapted from the official dbt documentation on incremental materialization.

While this setup absolutely works, over time we ran into several issues with it: 1. Imagine data changes for a day a week in the past. 1. With this approach there is not really a way to pick up this data other than full refreshing the table 2. Imagine you had some data integration issues before your model ran and for the latest day, only half the data was available and picked up. 1. Again – there is not really a way to fix this other than manually deleting this day or performing a full-refresh. 3. Now imagine the two above led to missing data in a bunch of incremental models that rely on each other. 1. You’re now in a world of pain where a simple incident mitigation can ruin your entire day, either full-refreshing a bunch of models or manually going through the dag and deleting a bunch of data before kicking it off again.
So how did we solve this
We follow the guidelines below in all our incremental models. We also have a macro that implements most of this for us that will be shared at the end of this post. This lets us solve the described issues in a single dbt command.
- Always set up your incrementals with a unique key! dbt will check for the unique key and either update the row with new values if there are any or create a row with this unique key. Find more about this in their documentation.
- If your unique key is a compound key – it is recommended to use surrogate key to create it, see their documentation
- Always set up your incremental statement with a variable, that defines how far into the past to integrate. We call this the days_back_to_update variable and it can be provided in the run command if necessary. That way, when we have to mitigate missing data, we can just provide this variable in the run and let dbt handle the dependencies.
- In addition, please provide a variable that allows you to offset the lookback window start date by a few days. This way we can rerun integration for a specific timeframe in the past. We call this the start_date_offset.
- For tables running on hourly please use the hours_back_to_update Same implications apply as above.
Our macro to implement this
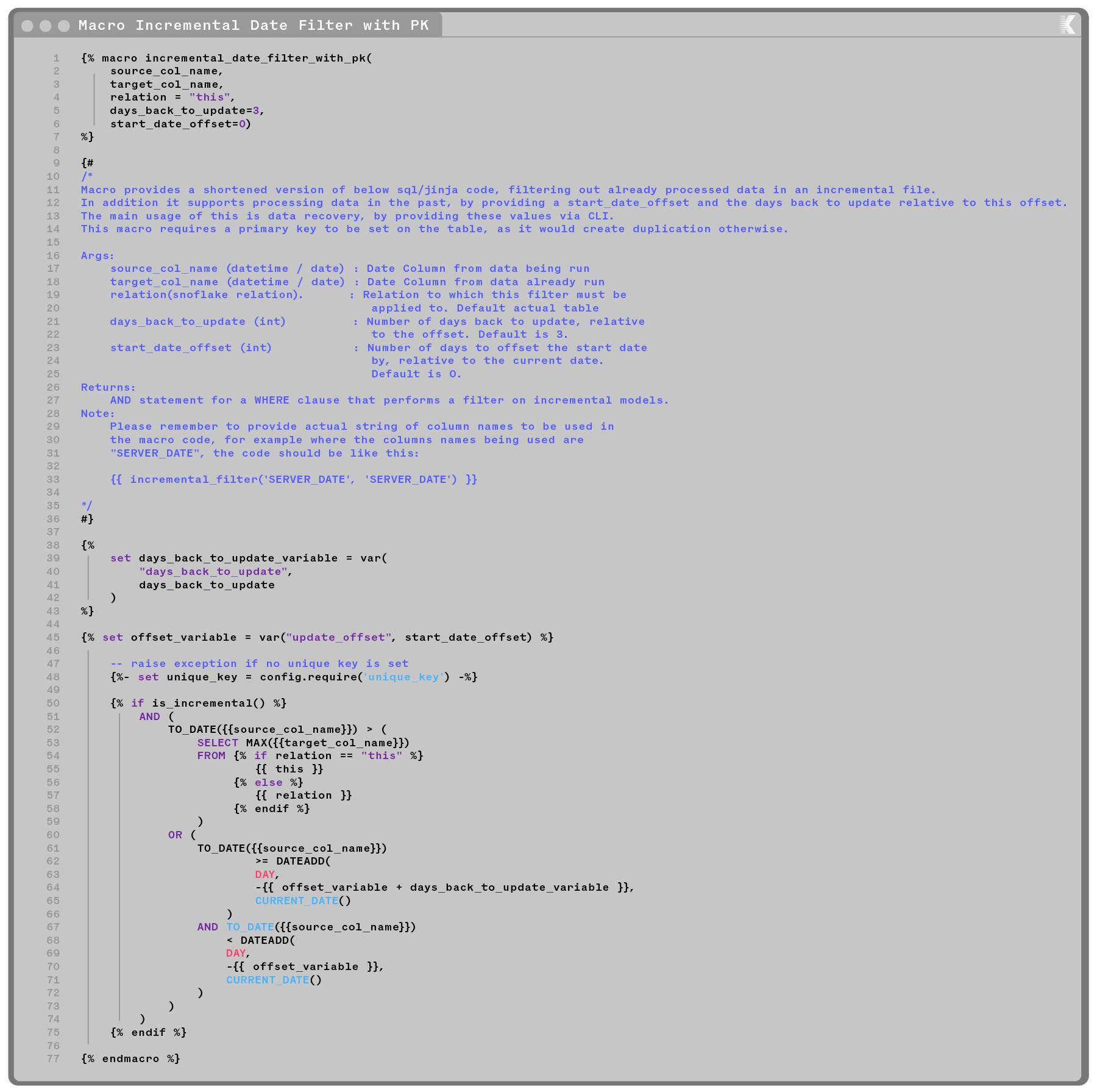
Using the query we used in the beginning to show a simple implementation of an incremental:

How does this solve our issues
Let us go back to the issues we identified and imagine we had a data incident from the 1st of April to the 2nd of April, because one of our sources played an Aprils fools on us. This led to data issues in the daily active users table as well as in a few incremental tables that rely on it. Today, it is the 7th of April.
How do we mitigate after retrieving the correct data from our data source?
Well – it is as simple as writing the following dbt command:

This means we start the mitigation 4 days ago – on the 3nd of April and mitigate 2 days, so until the 1st of April. If we have implemented the macro in all downstream incremental tables, they will pick this up as well and the new data will be used in the entire dag.
The entire mitigation is done in a single dbt command.
Closing thoughts
So this is how we turned our incident mitigation from a soul-crushing experience into a single dbt command. This obviously has some downsides to it: 1. Merging takes longer than appending, so you will likely notice a decrease in performance due to this 2. This is only really useful if it is implemented in the entire DAG, otherwise, you can’t just fire the mitigation on the entire downstream dependencies of a model and forget about it. 3. This – and any incremental logic for that matter – increases the complexity of a model. Make sure the potential performance increase is worth adding this complexity to your model.
How do you make your incrementals more robust? Let us know, so we can all worry less about incident mitigation and build more cool stuff!